Challenges remain in ego-centric 3D scene generation due to limited view overlap and the dominant influence of individual perspectives on scene interpretation.
These factors hinder the creation of viewpoint-consistent and semantically aligned visual content, as well as the construction of accurate geometric structures.
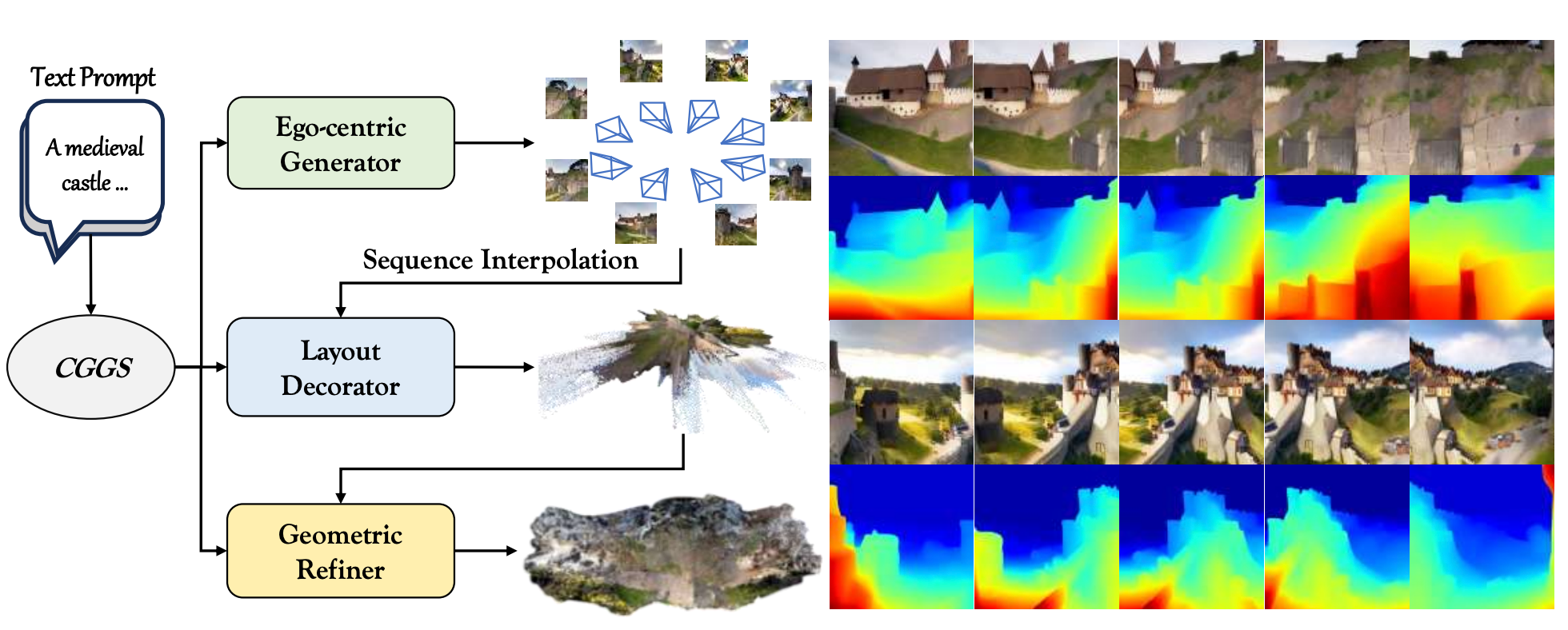
In this paper, we propose CGGS, a text-to-3D framework aiming to enhance 3D-content-awareness and address geometric distortions in ego-centric scene generation.
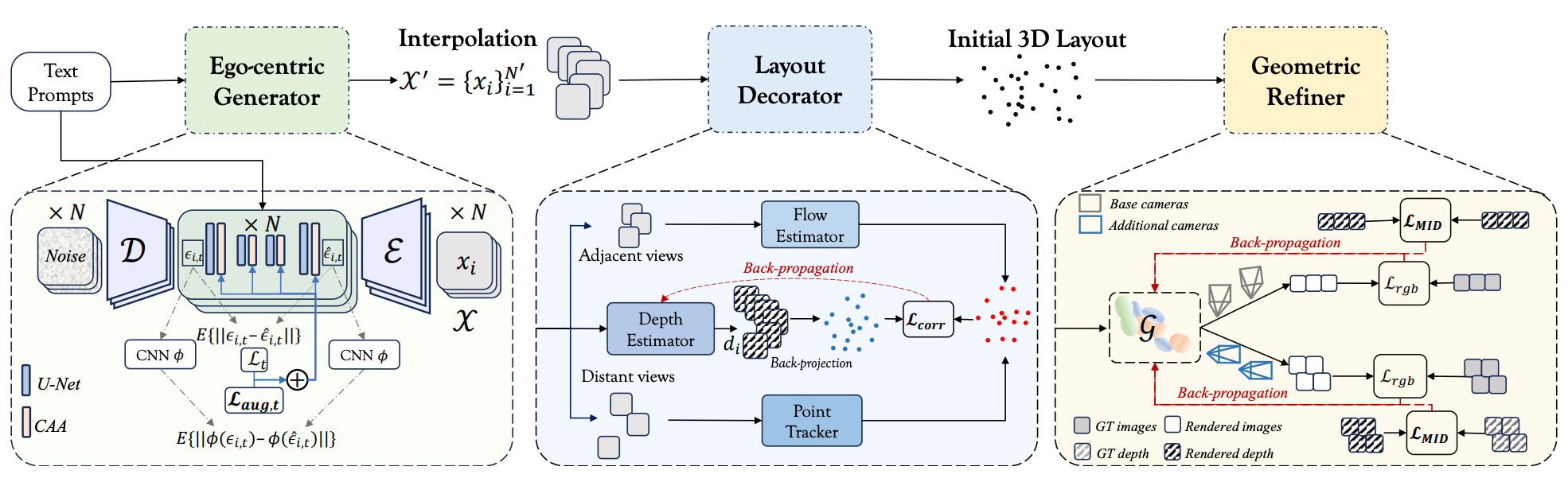
Firstly, the Ego-centric Generator is proposed by fine-tuning a Multi-View Latent Diffusion Model with consistency-augmented loss to generate consistent, high-fidelity 2D content aligned with textual descriptions.
Then, Layout Decorator leverages optical flow and point-track correspondence to estimate depth, therefore producing dense point clouds as coarse layouts from the ego-centric 2D priors.
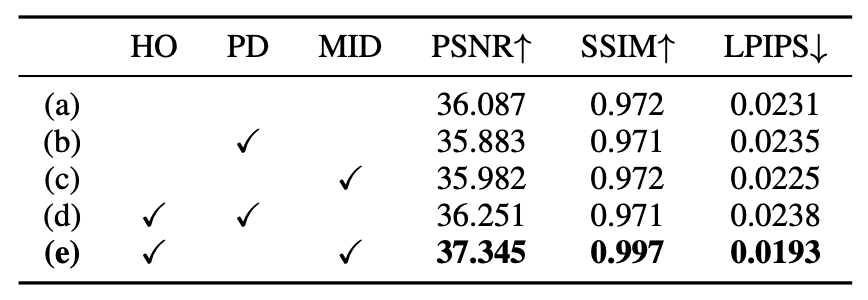
Building on this initialization, Geometric Refiner is proposed to enhance 3D Gaussian reconstruction via an entropy-based Mutual Information Depth Loss (MID) combined with a hierarchical optimization scheme for improving visual quality and geometric structure.
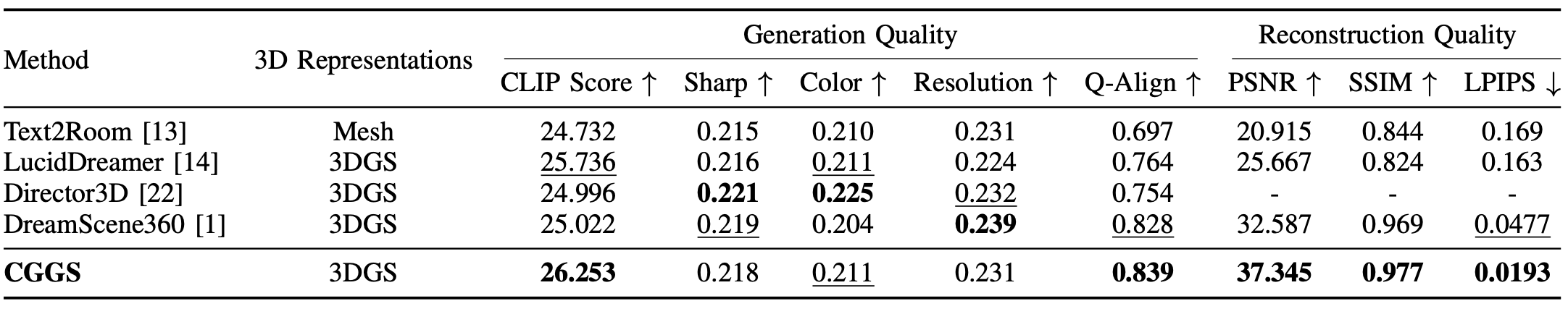
Comprehensive experiments demonstrate that CGGS outperforms previous methods in generating coherent and accurate text-driven 3D scenes.